Audiobook boxsets
February 25, 2020 in digital music by Dan Gravell
 Seems that these days, in our household, we have more children’s audiobooks running through our CD ripping workflow than music. Still, anything for a quiet car journey…
Seems that these days, in our household, we have more children’s audiobooks running through our CD ripping workflow than music. Still, anything for a quiet car journey…
At Christmas a family member gifted us this beauty:

Being a huge fan of Roald Dahl when I was younger I was eager to get this ripped and onto our car’s SD card!
Turns out, this was more difficult than most audiobook rips. The problems were…
- The books were actually MP3s on data CDs, not audio CDs.
- Each CD had one book, with one large MP3 file for the entire book.
- The MP3 files were untagged.
- There was no record of this boxset in MusicBrainz or Discogs (although there were similar box sets)
- The old questions resurfaced: how should boxsets be tagged?
Ripping… or not.
The first surprise was that each book was stored as an MP3 on each CD, but the CDs were data CDs, not audio CDs.
This meant this wasn’t so much a rip as a copy. At first I ran abcde as normal to extract (what I thought would be) some nice, lossless FLACs, but instead was greeted with errors about the CD being a data CD.
So instead I simply mounted the CD and found a solitary file on each one:
$ ls /media/cd/
Charlie and the Chocolate Factory.mp3
So it was a simple case of creating a folder in my music collection and copying one file on each CD there. There were sixteen CDs, so it took a while!
Monolithic files
Each book was stored in one file. For example, The BFG weighed in at 364MB.
More important than that - what about the listening experience? For players that don’t seek to the previous position it might be more flexible to have broken the files into chapters.
Broadly, I think it’s a good idea to keep some commonality between the files copied and the source data. If you don’t, recreating the library can get tricky, because you have to remember all changes made to the resulting structure of the files (I suppose we could apply the same reasoning to tagging too - see non-destructive editing common in photo management).
So at this point I began wondering about using CUE files and having an automated transformation script between the “gold” source library and the car library.
Untagged files
Given the audiobooks were distributed as MP3s, you would’ve thought a small amount of tagging could’ve been applied to the files. But actually, there were no tags at all:
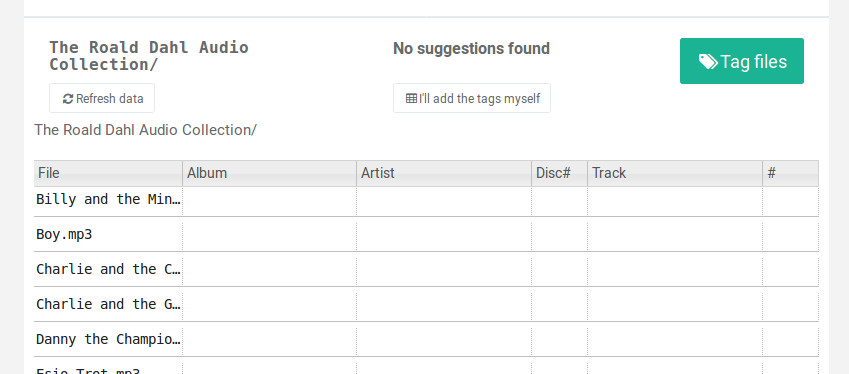
Some basic identification tags would’ve been useful.
So I resolved to tag the audiobook boxset in the following way:
Album- the name of the boxsetArtist- Roald Dahl - a short term convenience (it could’ve been the narrator with Dahl being theCOMPOSERDisc #- Use the ordering given on the back of the box setTrack- title of the book#- always 1 because there’s only one track per disc
This reflects the disc and track structure of the box set.
‘Unknown album’
Although there are a number of Roald Dahl CD boxsets, this particular one is not recorded online. I found some stores selling it, but there was no record in MusicBrainz or Discogs.
I’ve been talking to a few users about providing a feature to submit corrected data back to bliss, but for now I unlinked the one release bliss thought-it-was to avoid any false positives when correcting data.
Genre and year
The final tags I had to populate were GENRE and YEAR.
GENRE was easy; the same one I apply to all of my children’s audiobooks (for now) - simply Children’s.
YEAR was more difficult, as at the time I was tagging this release the boxset was in the car, being played via CD, so I couldn’t look for any information about the release date.
Fortunately I found the ISBN online - 9780241431993 and this gave the time of publication - December 2019. A new release! Which probably explains the boxset’s absence from online databases.
So now I was done, and the kids were ready to listen!
Thanks to Àlex Folguera for the image above.


