Music Library Management Chapter Three: Organising - tags
December 11, 2012 in digital music by Dan Gravell

Build a library of hundreds or thousands of albums and you can soon have a mess on your hands. One of the core problems is that the source of your music information is diverse: some is downloaded, some is fetched automatically from crowd sourced databases after ripping. Because there are multiple sources of information, they differ in their syntax and semantics. What one source will call a 'Rock' album will be called 'Alternative Indie' on another site.
These mislabelings make it difficult to search and navigate a music collection efficiently. This chapter is all about organising your music library's tags, making them consistent, correct and complete.
This is the fourth in a series of posts serializing the Music Library Management ebook.
Tags
Tags are the most flexible and portable way of recording information about your music. Tags are pieces of textual data stored within a music file. Strictly speaking, a tag refers to a collection of data, or fields, where each field has a key (e.g. 'album name') and a value ('Thriller'). There's a wide variety of different fields that can be stored.
When organising your collection it's likely that your music tags will be involved at some point. For instance, if you wanted to re-assign a group of albums to a new genre, that involves editing the genre tag for each file that is within each of those albums. If you simply want to rename an album, that means changing the album name tag in each file that makes up that album.
Different fields
So what is the different information available to you to tag your music? There's a wide range of possibilities. ID3 (http://www.id3.org/id3v2.3.0) is one tagging scheme which offers a wide possibility of different information that you can record. However, it's important to remember that you are bound by the limitations of your music player. If your music player does not display or search by these fields then it makes limited sense in recording the data. Different music players have different capabilities, and sometimes choosing what to tag and how to tag it is a combination of supporting lowest common denominators of music players.
De facto and de jure
Tagging evolved as a solution to storing more complex data about music than could otherwise be stored in a portable way. Originally, music collectors would write some information about the music in the file and folder names of their music. This had limitations, as more information was added the file and folder names would become unwieldy. For instance, for classical recordings fitting the composer, conductors, performers, orchestras and soloists into a filename is a hard task, and is similarly hard to read.
Tagging has evolved, and standards have always followed, rather than predicted, what information music collectors want to store. In the case of the aforementioned ID3 standard for MP3s, the wide scope of the standard means most bases are covered. Even here, though, problems arise. One of the more celebrated is how the artist for a released is tagged. Because the tags are typically recorded in each music file, each music file must store the so called "album artist". This can diverge from the track artist in many cases, and it's particularly common on compilation "Various artist" releases. Therefore, a separate tag was required for the album artist. In ID3 the TPE2 field, which according to the ID3 specification should be used for the band accompaniment for an artist, became used for "album artist".
Different music files means different tags
As mentioned, the ID3 format is the standard way of tagging MP3s. But what about FLACs, OGGs, MP4s and more? They all have their own tagging formats too. FLAC and OGG, for instance, use Vorbis Comments.
A complexity introduced here is that different tagging formats have different names for the tag fields. Whereas ID3 has standardised Txxx fields (TPOS, TALB and so on), Vorbis Comments define different field names for the same data.
Below I've gathered together the main tag fields, generalised their names, and listed how the field is represented in each respective tagging format:
Bare minimum
| Field name | MP3 | OGG | FLAC | MP4 |
|---|---|---|---|---|
| ID3v2 | Vorbis Comment | |||
| TRACK NAME | TIT2 | TITLE | @nam | |
| TRACK NUMBER | TRCK | TRACKNUMBER | trkn | |
| ARTIST | TPE1 | ARTIST | @ART | |
| RELEASE NAME | TALB | ALBUM | @alb | |
Useful
| Field name | MP3 | OGG | FLAC | MP4 |
|---|---|---|---|---|
| ID3v2 | Vorbis Comment | |||
| GENRE | TCON | GENRE | @gen | |
| YEAR | TYER | DATE | @day | |
| RELEASE ARTIST | TPE2 | ALBUMARTIST | aART | |
Elsewhere in this book I refer to the generalised names down the left hand column. When working with a particular file type, you should read along the row to find the actual tag that needs changing.
The three Cs of tagging
Since I've been building a large library over a long period of time, with music sourced from varying locations, I've noticed most organisational problems in a music library can be described as one or more of the 'Three Cs'. That is, completeness, correctness and consistency.
Completeness
As soon as you add new music to your music library, this is probably the first issue, if any, that you'll notice.
By 'completeness' I mean whether or not your music files' tags are actually filled in with information about your music. There are generally some 'required' fields, for these see below. In addition, there are probably tags that you will find especially useful for browsing your music or creating playlists; GENRE and YEAR tags are examples. Sometimes whether or not a tag is completed can be more subtle. For instance a tag may have a value, but it might be "Unknown", "Other" or some other useless data. You should probably treat such tags as incomplete too.
The completeness of your metadata is important to make it browseable and searchable. If you don't have this metadata inside your music files, your computer or music player cannot guess what music is 'punk'; it has to be told. This is done by making sure these tags are complete.
Generally, the bare minimum tagging an audio file requires depends on its use.
| Music track (in a single or album) | RELEASE NAME is the name of the wider single, album, EP etc. this track is part of, ARTIST is the performer of the track, TRACK NUMBER for the numbering of the track in the release, TRACK NAME for the name of the track |
| Music track (not formally released) | ARTIST is the performer, TRACK NAME is the name of the track |
| Podcast | RELEASE NAME for the name of the podcast, ARTIST for the principal presenter(s) of the episode, TRACK NUMBER for the episode number, TRACK NAME is the name of the episode |
Ensuring completeness of your music tags tends to be multi-faceted. The best way to start is to try to ensure that all music entering your collection has the tags you require from the start. This means using online music stores which provide comprehensive tagging. In addition, when ripping from CD, make sure the automated metadata lookup is successful. If you happen to have lost your connection to the Internet the lookup may fail, and you may need to retry later. More often than not it's easier just to postpone your ripping until a few hours later when you are Web-connected once more.
Try as you might, though, inevitably some music you import will lack all the tags you require. Furthermore, as time goes by you will no doubt discover and use more tags which are not present in your music library already. This means you need to perform the tagging yourself, and find a way of obtaining the information that should be inserted in the tags.
There are a number of ways of tagging. The most straightforward and often cited approach is to use a music tagger (discussed in more detail later) and good old Internet research. A music tagger is a software application that lists the tags already present in your files and allows you to add, change or remove them. Combined with a Web browser for Internet research you can scour the Web, find the information required and insert it into your tags.
For a large music collection, this will take a long time. It's easy to build a collection of hundreds or thousands of albums, therefore to research information for a tag for each album will take considerable effort.
Automated tagging is possible using some of the automatic taggers out there. They work by connecting to an online music database and retrieving the information you want to tag for each album. They identify the album either through its present tags or its 'acoustic fingerprint' (basically the audio contained within the music files). For a larger music collection automated tagging is invaluable but neither lookups via tags nor acoustic fingerprinting is 100% accurate, so watch out for false positives.
Whichever way you choose, once the tagging is complete it's normal to 'rescan' your music player so it picks up the changes you have made to your music.
Correctness
After noticing music that is simply lacking data, the next thing you'll notice are the glaring, and not so glaring but annoying-all-the-same, inaccuracies. Incorrect data makes browsing and finding music more difficult because the identification and classification of the music is inaccurate.
Once again, correctness tends to be a function of the source of the data. If you purchase music from online stores, the metadata that comes with the music is most likely to be correct, whereas CDs that are ripped with data coming from crowd sourced online databases are more likely to contain metadata errors. Indeed, metadata errors in ripped CDs are very common.
The problem is not the process of ripping, but the source of the metadata. As mentioned earlier, CD rippers tend to rely on an online music database called FreeDB. This has an enormous catalogue of metadata about released music. The reason it has such a large catalogue is that it is "crowd sourced" data. People like you and I have submitted metadata about given CDs and this metadata is subsequently downloaded by other people to use. It's a little like Wikipedia, except specifically for musical releases.
Almost inevitably, this introduces inaccuracies. Sometimes they are quite subtle, like a non-canonical album name. Other times they are obvious, such as a totally incorrect year of release. Either way they need fixing.
You can generally follow the same approach as when completing your tags; use a tagger and the Web to research, or use an automated tagger to do the work for you. In the former case you would need to change, rather than add, existing tags, and in the latter case the tagger should ideally identify where there are inaccuracies and offer to fix them for you. There are few software tools available to do this work. Finding data and inserting it is well covered, but understanding and alerting to errors is far less common.
But before we move onto consistency, we're not done yet. There's more than one type of correctness. I tend to separate correctness (and consistency, see below) into two forms: semantic and type. Semantic we've already covered and what most people think about when they refer to correctness. It's whether the data is correct in the world of music. Type correctness, on the other hand, refers to the way the tag data is entered.
For many simple character string tags this is not a problem. For instance, the RELEASE NAME for a track can be pretty much anything. Other tags, however, have constraints. For instance, the TRACK NUMBER should be an integer. In the early versions of ID3, GENRE had to be an integer between 0 and 79 inclusive. 'Country Music' was number 2, 'Reggae' was 16. Now, it's generally the responsibility of your ripper to make sure this data is correctly stored, but if you do any low level work with a music tagger you should make sure you obey type correctness.
Consistency
Consistency of music metadata is an aspect more subtle than completeness or correctness, but it tends to increase in importance over time and with music collections of ever increasing size.
Like correctness, I tend to split consistency into two subjects: syntactic consistency and semantic consistency. Syntactic consistency dictates whether all tags are formatted and typed in a standard format. Semantic consistency means the tag contents make sense semantically within the collection. More on semantic consistency later, but for now let's concentrate on syntactic consistency.
An obvious example of synactic consistency is with track numbers. The most basic way to store a track number is with a number: 1, 2, 10 and so on. One question is whether to left pad the track number with zeroes, and, if so, how many. Left padding is useful to make sure any application that reads the track numbers orders them correctly. If an application reads them and sorts them alphabetically tracks 1, 10, 11...19 will be shown before track 2. Forcing tracks 1...9 to be 01, 02, 03 avoids this problem. Because the maximum number of tracks on a CD is 99, left padding with one zero is normally sufficient.
Track numbers present further choices. A track number tag can also be formatted with the total number of tracks in the release. For instance, it may appear as "01/13" denoting the opening track on a thirteen track release.
Exactly the same formatting options present themselves with the DISC NUMBER tag with multi-disc releases, and so the same thoughts about synactic consistency apply here.
A final example, also related to multi-disc releases, is the formatting of the disc or media number in the RELEASE NAME. It's a common pattern to separate discs of a multi disc release by appending "[DISK I]", "(Disc A)" or "- Disk 1" to an RELEASE NAME. When importing music from different sources, different patterns can be adopted.
So why is syntactic consistency important in these examples? A lot of the time, syntactic consistency is adopted because it looks better. Having different ways of formatting release names, track numbers - and more - looks messy. If our goal is a beautiful, organised music collection, correcting these inconsistencies is important.
Other examples of syntactic consistency include:
- Date formats in date tags
- The replacement of the word 'The' in artist names (e.g. "Beatles, The")
Now, onto semantic consistency. Semantic consistency is about making the concepts represented by tags consistent across your music library. That sounds vague, but maybe that's because it can apply to anything in the 'music domain' that is represented in your tags.
A common example of semantic consistency is genre organisation. Genres can be recorded within music tags, and in most modern tagging systems this field is a free text tag where anything can be typed. Now, mis-spellings are one thing (more appropriately covered by 'correctness'), but even if each individual genre makes sense, that doesn't mean the set of all genres throughout your music collection is cohesive and usable.
When ripping CDs, genre is one of the fields imported from FreeDB, the crowd sourced metadata database. The genres that are imported are whatever happened to be in the submitter's head at the time. Some submissions are plain wacky, but it's more than likely you'll end up with an actual genre. Unfortunately, while one music lover may submit this information in very general terms, such as 'Rock', another might submit a much more specific genre, such as 'Avant-Garde Metal'. Quickly your music collection becomes populated with many different genres, some general, some specific and it becomes difficult to use this data to browse or search your collection.
If you purchase your music online from one store you should at least benefit from consistent genres, but when you combine them with other online stores further inconsistencies may arise. In theory if you purchase your music from one source then you should at least end up with a consistent set, but then consider what if that set is not to your liking?
Other examples of semantic consistency include:
- Use of original or re-release year for re-releases
- For classical recordings, what is recorded in the artist tag (e.g. composer or performer?)
Of the three Cs, consistency is probably the hardest to get right. This is probably because it is more rooted in the data you wish to see and use in your music collection and thus is also more subject to the whims you exact on your music collection. If you decide, say, to retrospectively add a new genre to your music collection, 'Heavy Metal', it is not difficult to find that genre for each new music file you add. However, to go through all existing music with a 'Rock' genre that should be reclassified as 'Heavy Metal' takes a lot more work.
It's this balancing of existing data and incoming data that makes consistency the hardest to manage aspect of your music collection. It is also why I first started work on bliss ( https://www.blisshq.com ).
Using music taggers
I've listed a lot of the problems inherent in digital music tagging, so now how do you solve them?
Well, the answer is: you use software. This software can operate at different levels of abstraction, but the most useful feature is that they write to the tags discussed previously. This means that however you reorganise your music it will be viewable and useable in all the different music players that you use: in your lounge, in your car and on your phone, for example.
A caveat: not all organisational software does write to the tags. Some store all the music organisational information in their own databases. An example is iTunes, where you have to make effort to actually commit any changes you've made into the music files tags. If this is the case, any re-organisation you make is not shared by other music players until you commit this data.
Of software that does write direct to tags, the software loosely breaks into two types. The first are the 'music taggers'. These are low level software that simply list all of your files and all of the tags for those files in a spreadsheet style layout. You generally must make sure that you edit files together, where applicable, for example when changing the genre for an album you should change the GENRE tag for each file within the album. Examples of music taggers are MP3Tag ( http://www.mp3tag.de/en/ ) and Jaikoz ( http://www.jthink.net/jaikoz/ ).
In addition there are higher level music organisers that attempt to display and edit music at a higher level of abstraction using musical domain terms; album, release, artist and so on. For instance, if you change the genre for an album, all of the tags for all of the files for the album will be changed for you. This can be a little less error prone. Examples of music organisers are Media Monkey ( http://www.mediamonkey.com/ ) and bliss ( https://www.blisshq.com ).
In terms of the sheer scope of what each type of software can do, music taggers are generally more powerful, if harder to use and more error prone. However, learning how to use them can aid your understanding of music management, as it exposes all of the tags present in your music files. Furthermore, when trying to figure out why your music player simply won't display things the way you want, the only option may be to resort to a music tagger to see what tags are causing the problem. For this reason, and because they are the most consistent category in terms of look and feel, I'll give a tour of a popular music tagger.
Music taggers have a common appearance. Upon loading, they show a spreadsheet style view as below:
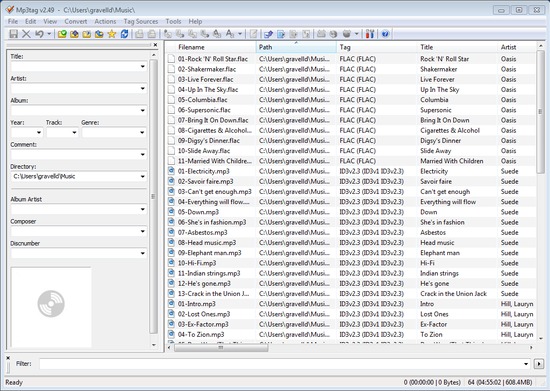
Some music taggers show only the table, and allow values to be edited inline inside the table. In the case of MP3Tag, you select the file you want to edit, then edit the values in the tag panel on the left. Here's an example with a file selected:
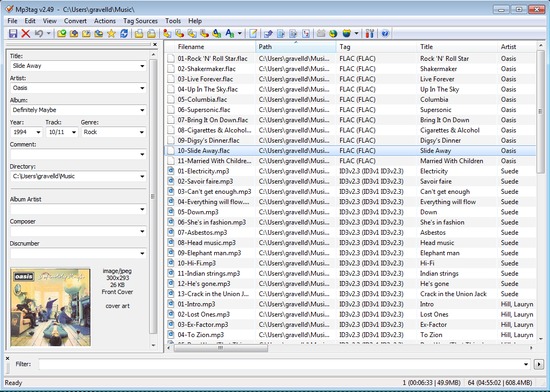
In this example, one could easily edit the ARTIST tag by editing the text in the Artist: field. Typically, a music tagger allows you to select many tracks at once so that the same tag can be changed to one consistent value. This is obviously useful for editing album-wide settings, such as album name and artist name.
Music taggers also typically have a semi automated dimension to automate a set of conversions. These may include:
- Changing the letter case of album and artist names (e.g. Rolling Stones or Rolling stones)
- Synchronising file and folder names with tags
This is where tagger capabilities diverge, so without trying to guess which one you will use I'll leave the tagger examples there.
Thanks to frannie60 for the image above.


