Splitting audiobooks into chapters with AI and crossed fingers
January 22, 2021 in digital music by Dan Gravell
 About a year ago I blogged about organising audiobook boxset files. The organisation scheme I derived has proven itself pretty useful. But there was always one problem with that particular boxset: monolithic audiobooks.
About a year ago I blogged about organising audiobook boxset files. The organisation scheme I derived has proven itself pretty useful. But there was always one problem with that particular boxset: monolithic audiobooks.
Monolithic audiobooks are audiobooks packaged in one audio file. For smaller books you might get away with it, but for some of the books in that collection, such as Charlie and the Chocolate Factory, you’re talking about one unwieldy MP3 file (I would normally rip a CD in FLAC format, but in this CD boxset the audio actually comes as an MP3 file on a data CD).
What’s the problem with one MP3 file? Mainly: seeking. It’s typical you won’t finish the audiobook in one sitting. Your music player might be sophisticated and remember your position in a particular file but many aren’t. In my case we tend to play these stories in the car for our children and our car’s stereo is definitely not sophisticated.
Split to files, or CUE sheets?
How you go about splitting an audiobook depends on what you want the result to be.
The obvious result is a bunch of new audio files, created from the original monolithic file. This is fine, although it does have the disadvantage of being less “true” to the original source material. That might not particularly bother you, although there are a number of disadvantages for collectors.
You can avoid this with an additive solution. CUE sheets are text files that, for a source audio file, describe where each constituent track should start and end. It also allows the tracks to have metadata. It’s not the greatest analogy, but think of CUE sheets a little like playlists in reverse - it splits audio rather than joining it.
Ideally I would use a CUE sheet. However, my car’s music player is not even capable of reading ID3v2 tags, so the likelihood of it reading a CUE sheet is non existent. Therefore, due to that constraint, I have to split the files.
In the end I actually did both; a CUE sheet is a convenient way of storing track points in a standardized format that can be fed to splitting tools, so I ended up generating one.
Different approaches to splitting audiobooks
Above, I decided I wanted separate files as an output to this process.
To get there, I needed to work out:
- Where the chapters start in the audio file.
- How to get these positions into a splitting tool so the file can be split.
The ‘traditional’ solution to finding the chapter start points is to use an audio editor or viewer to view the waveform of the audio file and discern where the chapters start from there.
A common solution is Audacity but if you’re just looking for the cut points then an online viewer could work - take a look at http://naomiaro.github.io/waveform-playlist/newtracks.html - no uploading involved.
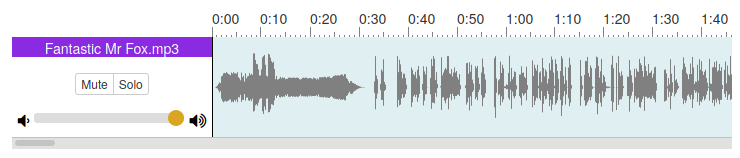 Good luck finding the chapter breaks there…
Good luck finding the chapter breaks there…
Regardless of the tool you use, the disadvantage of this is that it’s quite manual. Points of silence in the waveform may be the start of a chapter… or they may not. It can be frustrating to scan from silence to silence looking for the correct gap.
Being a geek, I thought… how about we apply AI (Artificial Intelligence) to the problem? In this case - a form of AI called machine learning (ML).
Finding the chapter breaks with machine learning using Vosk
There are a number of speech-to-text services out there. You might already have used one - examples are IBM Watson and Google Cloud Speech. These are used by automated translation services you might have on your smartphone.
However, I figured it would be easier to get up and running with some software on my own computer - I am a self hoster after all!
It turns out that Vosk is really easy to get started with.
I followed the installation instructions for Vosk. First, I needed to get Python3 and pip up to date. Once that was done, installing was as simple as:
$ pip3 install vosk
Vosk requires a decoded mono WAV file with a sample rate of 16kHz. It’s unlikely that your audio file is in that format, and this one certainly wasn’t. So, I used ffmpeg to decode the audiobook’s MP3 files. So long as the decoded WAV file’s durations are the same, the original source can be used as the subject of the split.
ffmpeg -i Fantastic\ Mr\ Fox.mp3 -ar 16000 -ac 1 Fantastic\ Mr\ Fox.wav
Now it was time to run Vosk. First, we download the English language trained models:
git clone https://github.com/alphacep/vosk-api
cd vosk-api/python/example
wget https://alphacephei.com/kaldi/models/vosk-model-small-en-us-0.15.zip
unzip vosk-model-small-en-us-0.15.zip
mv vosk-model-small-en-us-0.15 model
The model is the pre-trained ML layers that encode what has been learnt about speech, i.e. which sounds relate to which words.
Now we can run Vosk to convert the speech in the audiobook to text!:
python3 ./test_srt.py Fantastic\ Mr\ Fox.wav > Fantastic\ Mr\ Fox.srt
If you’re wondering how long this takes - it took about five-and-a-half minutes on my fairly underpowered (by modern standards) workstation. The audiobook is a bit over an hour in length.
There are a number of ways Vosk can output its findings. In this case I generated an .srt file.
The first time I ran this I was extremely curious to see the transcription. Would it be gobble-de-gook?
$ head -n 20 Fantastic\ Mr\ Fox.srt
1
00:00:08,310 --> 00:00:11,790
fantastic mr fox i roll down bred
2
00:00:11,790 --> 00:00:12,750
by chris order
3
00:00:33,150 --> 00:00:35,490
chapter one the three farmers
4
00:00:37,770 --> 00:00:39,120
down in the valley there were three
5
00:00:39,120 --> 00:00:39,780
farms
I was actually pretty astonished that anything English came out.
Looking at the transcription, there are some obvious errors. “i roll down” was actually “by Roald Dahl”. “bred by chris order” should actually be “read by chris o’dowd”. However, I could see “chapter one” which encouraged me - if the chapters could be distinguished, maybe this could work…
I’m using Linux, so I can then grep (search for text) in the .srt file:
$ grep -B1 -A4 "chapter" Fantastic\ Mr\ Fox.srt
00:00:33,150 --> 00:00:35,490
chapter one the three farmers
4
00:00:37,770 --> 00:00:39,120
down in the valley there were three
--
00:02:30,600 --> 00:02:32,910
chapter two mr fox
48
00:02:35,100 --> 00:02:37,380
on a hill above the valley there
--
00:05:36,600 --> 00:05:37,410
chapter three
115
00:05:38,190 --> 00:05:38,820
the shooting
--
... [and much more]
Each -- line demarks a separate finding of “chapter” by grep.
This gives all the chapter markers in the book! Viewing all that was found, I could see that all the chapters had been discovered, although about 25% of the chapter titles were a little wrong. But still, this is a big improvement on manually reviewing the audiobook using a waveform viewer.
If you’re interested, I uploaded the greped findings:
Creating a CUE sheet to facilitate the split
With the track markings I now had to decide how to split the audiobook file. I could have just copied and pasted this into commands to perform the split.
However, CUE sheets are a standardised way of describing these points (amongst other things). They can be used as the input to an audio splitter. I realised it would make it easier to trial different software with a CUE script.
CUE sheets are text files so you can write them by hand, but I used CUE Generator. I simply copy and pasted the chapter names and start times in the same format into CUE Generator:
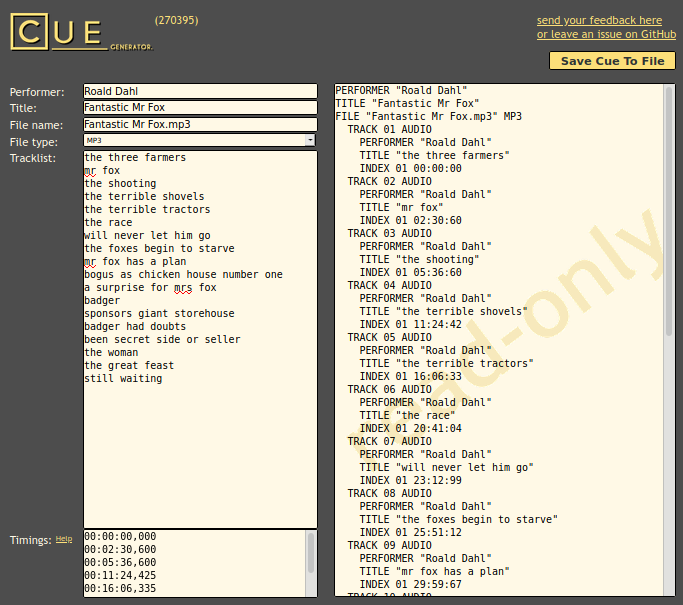
Happily, the beginning timestamp for each track “just works” in terms of the CUE script understanding the time format. However, you might to lower the start point by 1s or so to give a little gap before the speaking starts.
The resulting CUE sheet was…
I know - there are a few issues with the metadata there. Capitalisation can be done by bliss later.
Splitting the MP3 with mp3splt
The standard approach to splitting audio files in Linux is shnsplit. However, shnsplit doesn’t accept MP3s as input. I could’ve decoded the MP3 to a WAV but that would’ve been an extra step. Instead, I found the slightly annoyingly named mp3splt. It’s not mentioned on the Github page, but it’s available in the Ubuntu repos and was an easy install.
All we need to do is feed the CUE sheet and the original file to mp3splt
$ mp3splt -c Fantastic\ Mr\ Fox.cue Fantastic\ Mr\ Fox.mp3
mp3splt 2.6.2 (09/11/14) - using libmp3splt 0.9.2
Matteo Trotta <mtrotta AT users.sourceforge.net>
Alexandru Munteanu <m AT ioalex.net>
THIS SOFTWARE COMES WITH ABSOLUTELY NO WARRANTY! USE AT YOUR OWN RISK!
Processing file 'Fantastic Mr Fox.mp3' ...
reading informations from CUE file Fantastic Mr Fox.cue ...
Artist: Roald Dahl
Album: Fantastic Mr Fox
Tracks: 18
cue file processed
info: file matches the plugin 'mp3 (libmad)'
info: found Xing or Info header. Switching to frame mode...
info: MPEG 1 Layer 3 - 44100 Hz - Joint Stereo - FRAME MODE - Total time: 75m.46s
info: starting normal split
File "Roald Dahl - 01 - the three farmers.mp3" created
File "Roald Dahl - 02 - mr fox.mp3" created
File "Roald Dahl - 03 - the shooting.mp3" created
File "Roald Dahl - 04 - the terrible shovels.mp3" created
File "Roald Dahl - 05 - the terrible tractors.mp3" created
File "Roald Dahl - 06 - the race.mp3" created
File "Roald Dahl - 07 - will never let him go.mp3" created
File "Roald Dahl - 08 - the foxes begin to starve.mp3" created
File "Roald Dahl - 09 - mr fox has a plan.mp3" created
File "Roald Dahl - 10 - bogus as chicken house number one.mp3" created
File "Roald Dahl - 11 - a surprise for mrs fox.mp3" created
File "Roald Dahl - 12 - badger.mp3" created
File "Roald Dahl - 13 - sponsors giant storehouse.mp3" created
File "Roald Dahl - 14 - badger had doubts.mp3" created
File "Roald Dahl - 15 - been secret side or seller.mp3" created
File "Roald Dahl - 16 - the woman.mp3" created
File "Roald Dahl - 17 - the great feast.mp3" created
File "Roald Dahl - 18 - still waiting.mp3" created
Processed 174046 frames - Sync errors: 0
file split (EOF)
And those files were output!
Yes, again I know the filenames and tags leave a lot to be desired. But, again, we can fix the file paths and edit the tags in bliss later.
Here’s an example result:
That should make car journeys easier!
Photo by Markus Spiske on Unsplash


