Music data pipelines
May 01, 2012 in digital music by Dan Gravell

The metadata in your music files contains important identifying and classifier information. These tags make your music collection more searchable, navigable and all round easier-to-use. Fortunately, several online music databases offer a wealth of information that you can use to improve your digital music library.
If it's so easy to source extra data for your music collection then it's tempting to add more and more data, but this adds a maintenance burden because you must ensure your own customisations of that data are repeated. Thinking about retrieving data and tagging this information in your music files as a pipeline that can be documented and repeated helps solve inconsistencies that can emerge.
Tagging from source
Tags are sourced from various places. If you rip CDs, the ripper software looks up the data online and tags it for you. If you purchase and download music then the tags are probably already completed for you, in a manner decided by the online store from which you purchased the music. Either way this is data sourced online, but there are problems with this.
These tags can be incomplete, inconsistent or incorrect. Important data you normally rely on to form playlists, for example, may be missing. The album name may be formatted with a case that you don't find visually appealing, or is inconsistent with your other music. Track numbers may be missing padded zeroes, or it may have them and you don't want them. There are many examples, but it all adds up to a lot of re-organisation work.
These problems would go away if you had documented, repeatable ways of customising the data sourced online, and a way of intercepting the tagging process. In most cases intercepting the initial tagging of files is not possible. If you purchase the music online, the tags are shipped with the music files and what you see is what you get. When ripping CDs you often have a little more opportunity to edit the incoming tags, but these are still manual tasks with little help from software.
So it's often during the re-organisation phase, combing through your music files with MP3 tagging software, that you get the chance to customise your music's metadata. Many such software offers the opportunity to automatically download metadata from online databases. The trouble comes again: how to customise this incoming data so that it both appeals to my own aesthetic tastes and it remains consistent with the rest of my library?
I've found one mental model for this: a music data pipeline.
Music data pipelines
Visualise a pipeline flowing with textual metadata about your library, with the start of the pipe being a music database, and the end being the tagging inside your music files.
The simplest possible pipe is just that: a two stage process which fetches the data online and inserts it into your music files. Many auto taggers do this for you already.
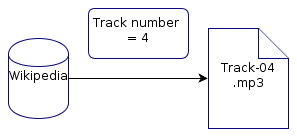
That works, but ensuring consistency is a pain. Next, add steps to the pipeline to customise the data you are discovering. Imagine you want all single track numbers to be padded with one zero:
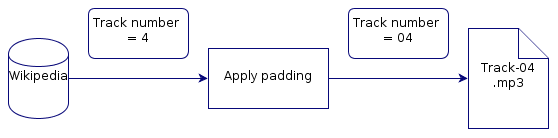
Chained together, you can imagine this data being customised to your liking. Some of these pipelines are simple, like the example. Others might require more input data and may completely change the eventually tagged information. For example, you may have decided to adopt the fundamental music genre list but a music database, instead, offers a very specific genre. By searching for a generalised form of the genre, you may find a genre that is consistent with the coarse grained genres you prefer.
Pipelines are one way of visualising this, but they aren't the only way. I think the important thing is to acknowledge that the temptation to incorporate extra metadata into your music files will open up new opportunities for inconsistencies. Documenting and applying processes to resolve these inconsistencies are what's important.
Thanks to David C. Foster for the image above.


